
Panduan ini akan membahas cara melakukan inference VibeVoice Large Quantized 8-bit (Q8) di Google Colab secara gratis. VibeVoice adalah framework text-to-speech (TTS) open-source inovatif yang dikembangkan oleh Microsoft Research untuk menghasilkan audio percakapan multi-speaker yang ekspresif dan berformat panjang, seperti podcast hingga 90 menit dengan maksimal 4 pembicara berbeda.
Microsoft telah menonaktifkan repositori GitHub resmi VibeVoice karena kekhawatiran terkait potensi penyalahgunaan teknologi suara sintetis berkualitas tinggi untuk deepfake, penipuan, atau penyebaran disinformasi. Namun, sifat open-source dari VibeVoice telah memungkinkan komunitas untuk mem-fork repositori tersebut dan terus mengembangkannya. Banyak developer telah membuat salinan dan bahkan menghasilkan versi quantized yang lebih efisien dari model original, memberikan fleksibilitas kepada pengguna dengan berbagai sumber daya hardware.
Varian Model VibeVoice yang Tersedia
Berikut adalah beberapa varian model VibeVoice yang tersedia di komunitas saat ini:
Model Original:
- VibeVoice-1.5B (microsoft/VibeVoice-1.5B): Sekitar 5,4 GB, model base yang lebih ringan dan cukup untuk kebanyakan kebutuhan.
- VibeVoice-Large (aoi-ot/VibeVoice-Large): Sekitar 18,7 GB, model 7B parameter dengan kualitas tertinggi namun memerlukan VRAM yang sangat besar.
Model Quantized:
- VibeVoice-Large-Q8 (FabioSarracino/VibeVoice-Large-Q8): Sekitar 11,6 GB, menggunakan quantization 8-bit yang mempertahankan hampir semua kualitas audio original sambil mengurangi kebutuhan VRAM dari 18,7 GB menjadi 11,6 GB. Model ini menggunakan teknik quantization selektif di mana hanya 52% dari parameter yang aman dikuantisasi, sementara 48% sisanya tetap dalam presisi penuh untuk mempertahankan komponen kritis audio.
- VibeVoice-Large-Q4 (DevParker/VibeVoice7b-low-vram): Sekitar 6,6 GB, versi quantization 4-bit yang jauh lebih ringan dan dapat berjalan di GPU dengan VRAM lebih kecil, meskipun dengan sedikit penurunan kualitas audio.
Keberadaan berbagai varian ini memberikan fleksibilitas kepada pengguna untuk memilih trade-off antara kualitas audio, kebutuhan memori, dan kecepatan inference sesuai dengan sumber daya hardware yang mereka miliki.
Google Colab sebagai Solusi Akses GPU Gratis
Meskipun versi quantized telah mengurangi kebutuhan VRAM secara signifikan, kenyataannya banyak pengguna masih tidak memiliki akses ke GPU yang memadai. GPU kelas menengah seperti RTX 3060 atau 4070 Ti dengan 12 GB VRAM masih merupakan investasi yang cukup besar. Platform online seperti Hugging Face memiliki keterbatasan dengan tier gratis yang membatasi jumlah inference, sehingga pengguna biasanya sudah mencapai batas setelah beberapa kali generate audio saja.
Di sinilah Google Colab menjadi solusi ideal. Google Colab menyediakan akses gratis ke GPU NVIDIA T4 dengan 15 GB VRAM, yang lebih dari cukup untuk menjalankan model VibeVoice Large Q8 yang hanya memerlukan 12 GB. Tier gratis Colab memiliki batasan waktu penggunaan beberapa jam per hari, namun jauh lebih generous dibandingkan platform lain. Yang membuat Colab menarik adalah kemampuannya menjalankan notebook Jupyter secara langsung di browser tanpa instalasi apapun, sehingga pengguna dapat menulis kode, mengeksekusinya, dan melihat hasilnya secara real-time dengan memanfaatkan hardware Google Cloud secara gratis.
Langkah-Langkah Menjalankan VibeVoice di Google Colab
Berikut adalah panduan lengkap untuk menjalankan VibeVoice menggunakan Google Colab. Pastikan Anda memiliki akun Google untuk dapat mengakses Google Colab secara gratis.
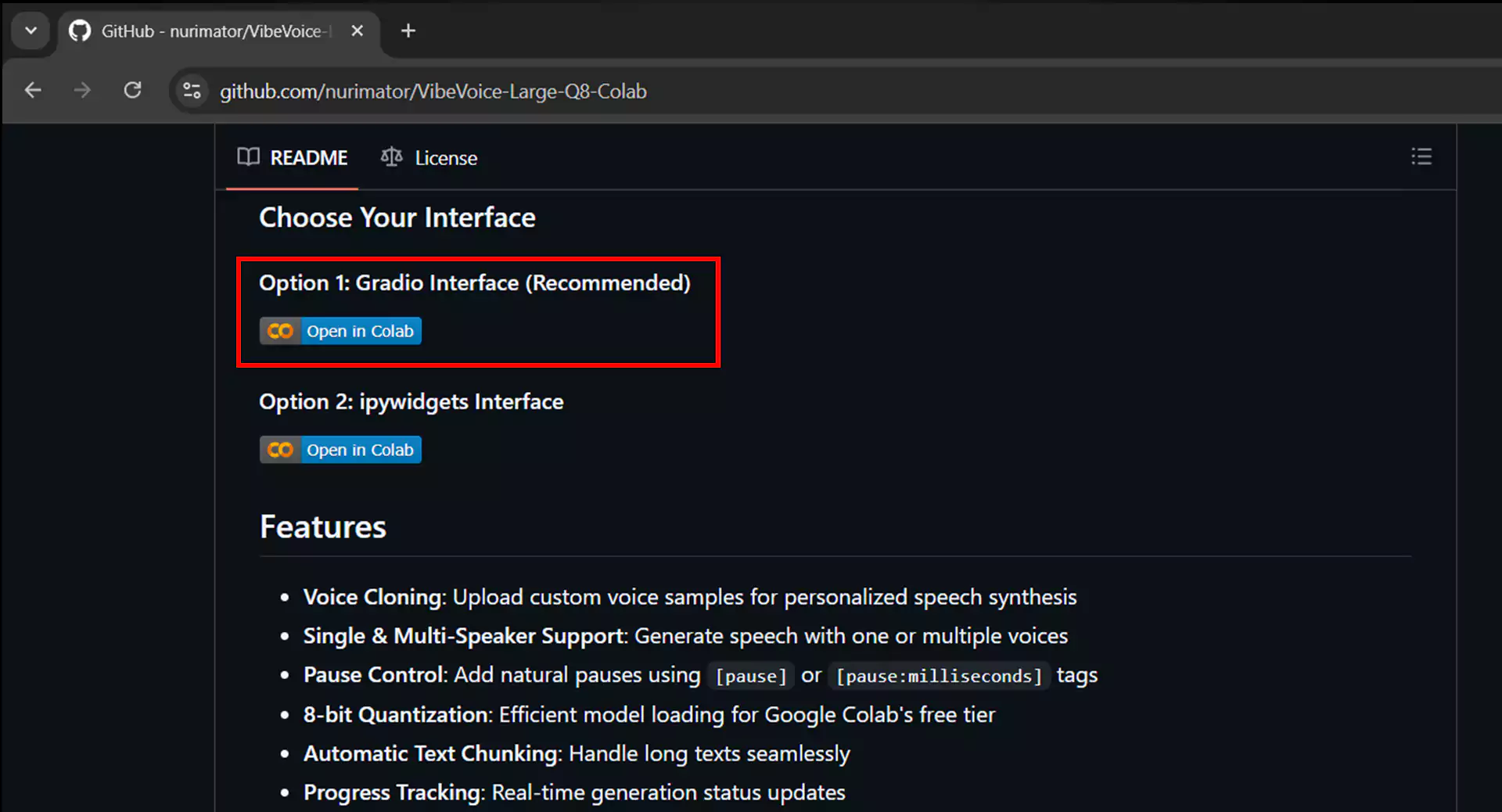
1. Mengakses Notebook Google Colab
Kunjungi link repositori VibeVoice yang telah disiapkan khusus untuk Google Colab di https://github.com/nurimator/VibeVoice-Large-Q8-Colab. Scroll ke bawah hingga menemukan dua pilihan inference, yaitu interface Gradio dan interface IPyWidget. Kami merekomendasikan memilih interface Gradio karena lebih user-friendly. Klik tombol Open in Colab pada bagian tersebut, dan Anda akan diarahkan ke halaman Google Colab dengan notebook yang siap digunakan.
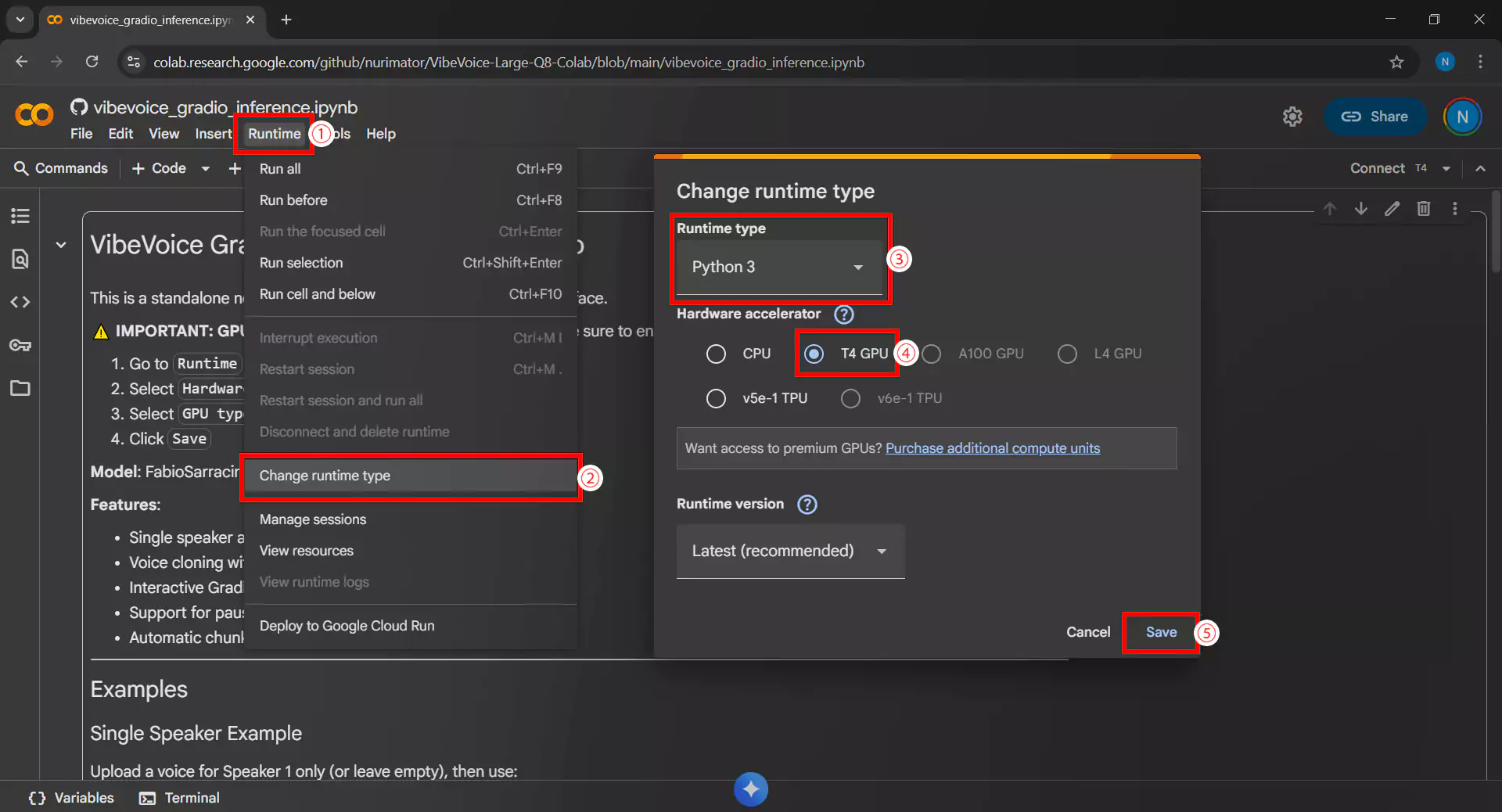
2. Mengatur Runtime GPU
Pastikan menggunakan runtime dengan GPU untuk menjalankan model VibeVoice. Caranya sebagai berikut
- Klik menu Runtime lalu Change runtime type
- Pada bagian Hardware accelerator, pilih T4 GPU
- Pastikan Runtime shape diatur ke Standard
- Klik Save untuk menyimpan pengaturan
- Pastikan juga environment menggunakan Python 3
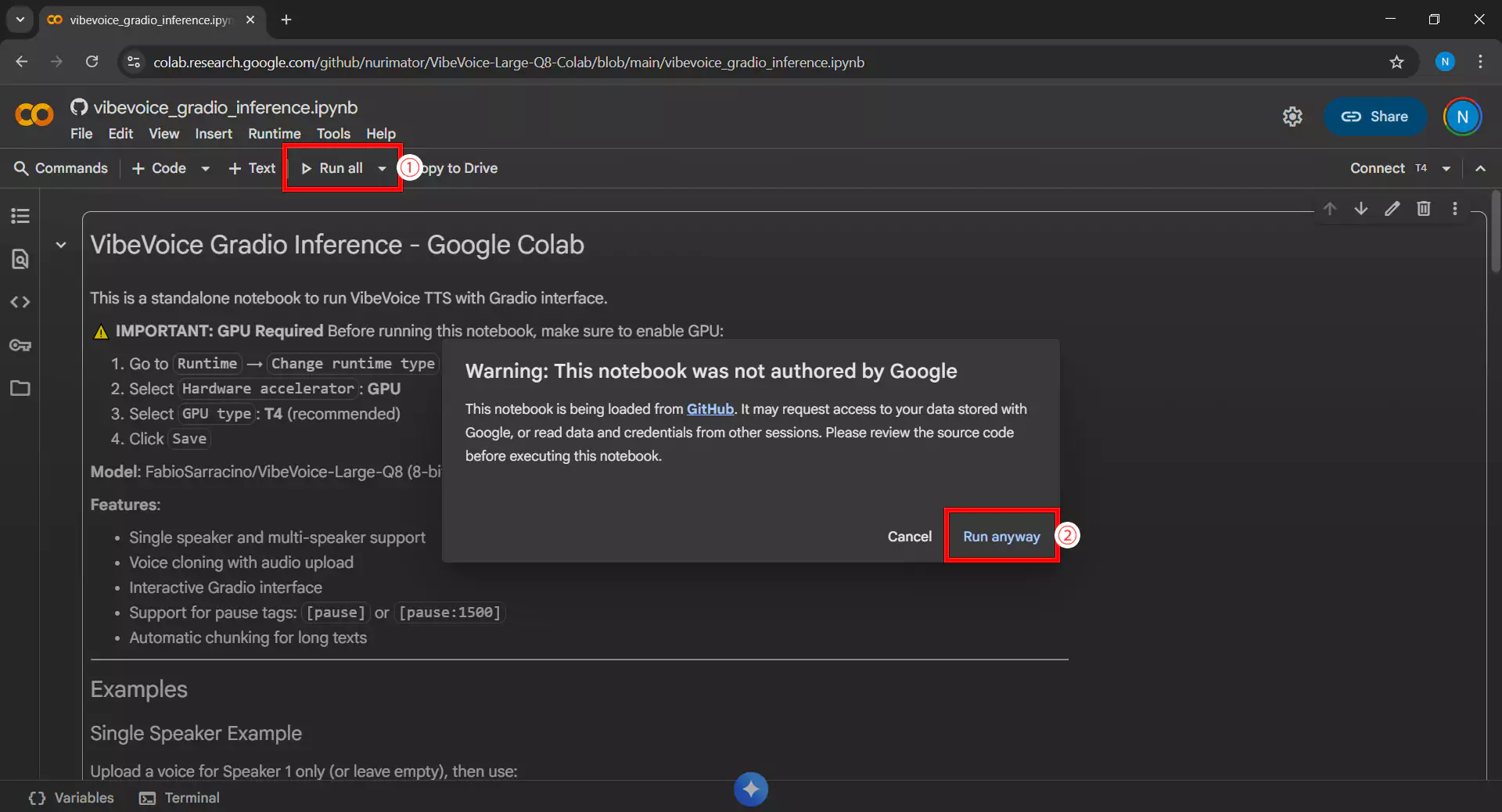
3. Menjalankan Semua Cell
Klik Run all cells atau gunakan shortcut Ctrl+F9 untuk menjalankan semua kode dalam notebook secara berurutan. Jika muncul peringatan yang meminta izin akses atau konfirmasi keamanan, klik Run anyway atau Izinkan untuk melanjutkan proses.
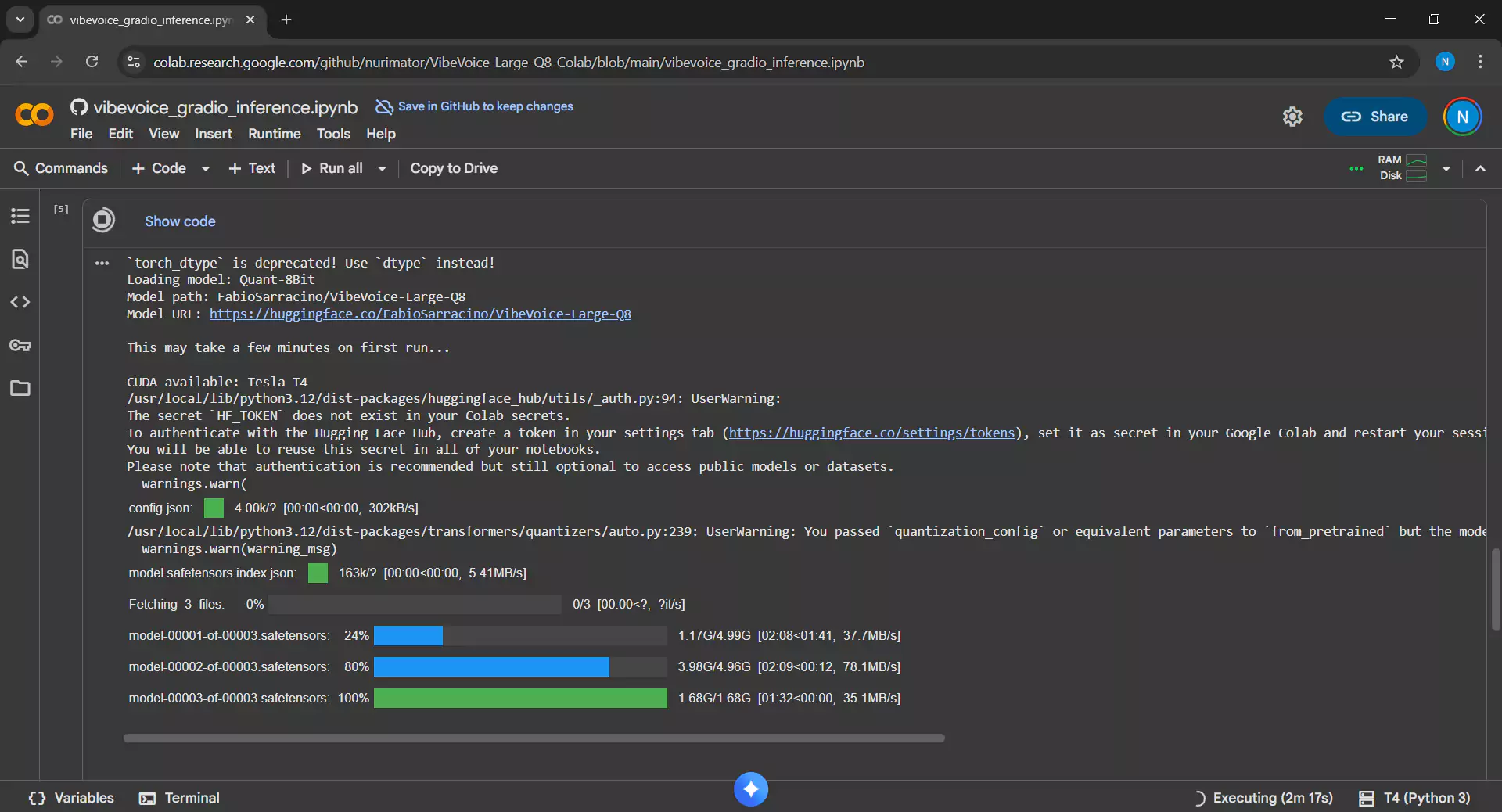
4. Menunggu Proses Download dan Setup
Proses ini memakan waktu 5-10 menit karena akan melakukan hal-hal berikut
- Mengunduh model VibeVoice Large Q8 berukuran sekitar 11,6 GB
- Menginstall semua dependensi yang dibutuhkan
- Menyiapkan environment inference
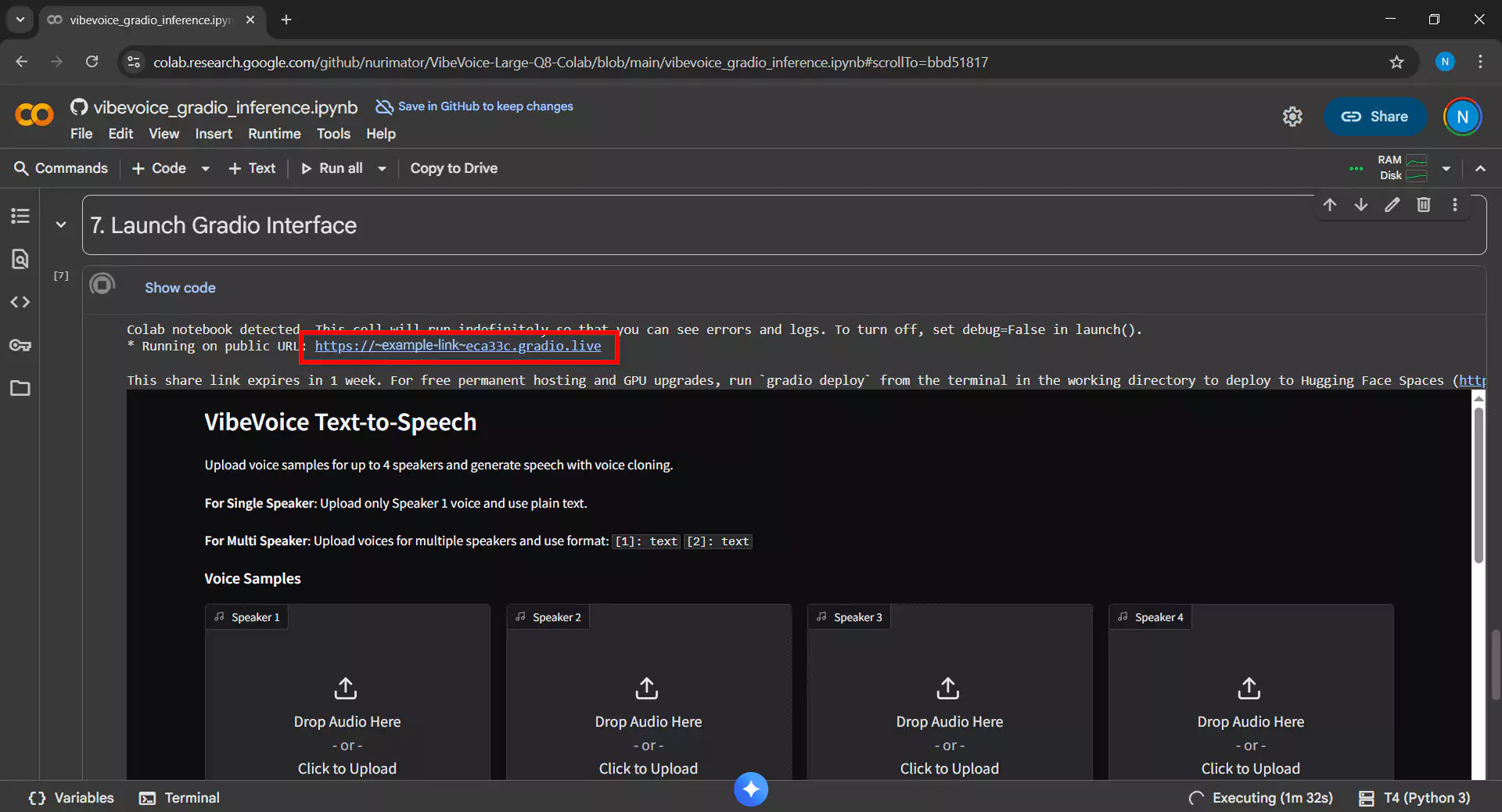
5. Mengakses Interface Gradio
Setelah semua cell berjalan tanpa error, akan muncul link Gradio pada output cell terakhir dengan format seperti https://xxxxx.gradio.live. Klik link tersebut untuk membuka interface VibeVoice dalam tab baru di browser Anda.
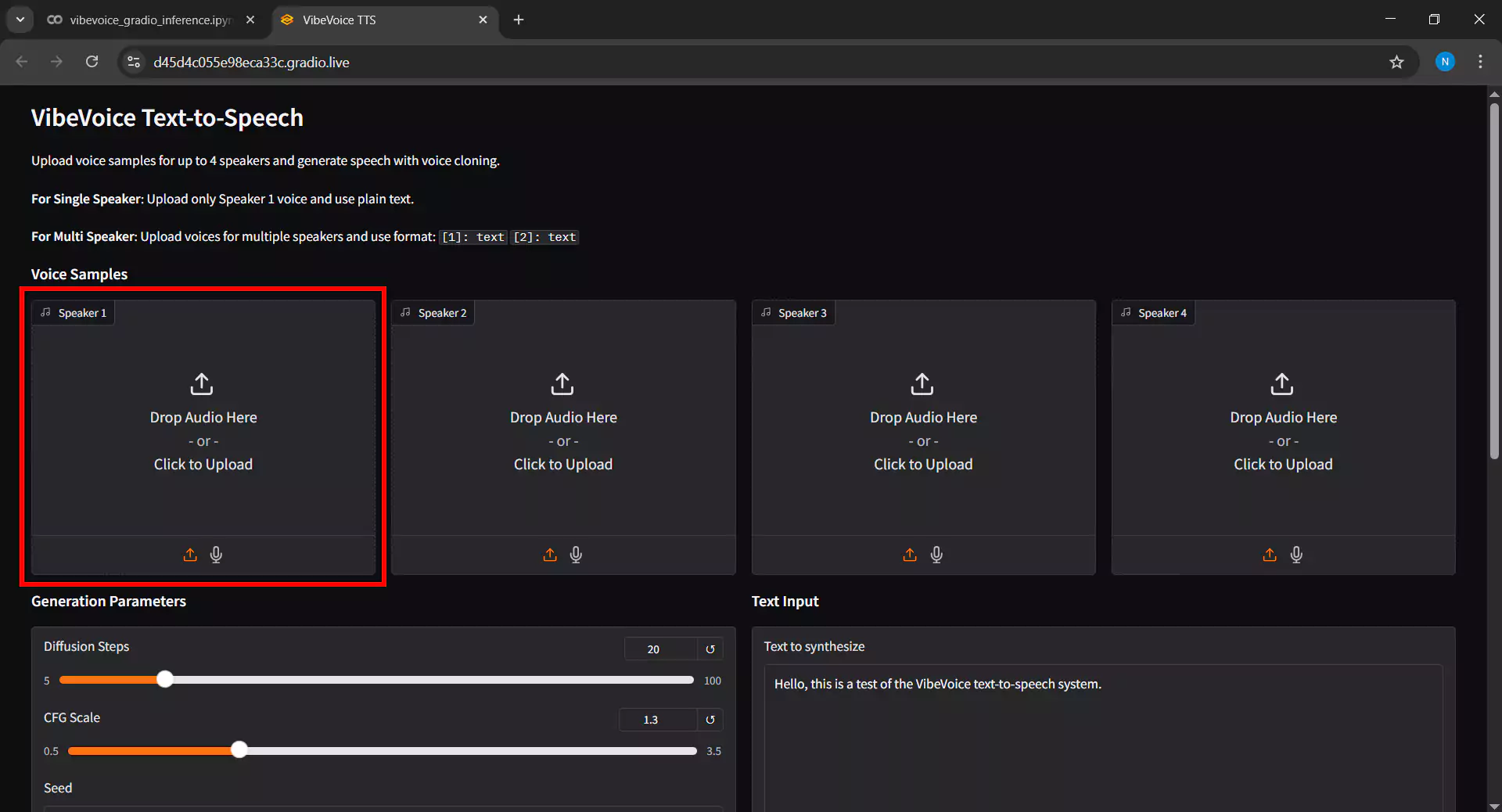
6. Mengupload Voice Sample
Pada interface Gradio, langkah pertama adalah mengupload voice sample sebagai referensi suara dengan cara sebagai berikut
- Klik tombol Upload pada bagian Voice Sample
- Pilih file audio berformat WAV atau MP3 dari perangkat Anda
- Tips untuk hasil terbaik gunakan audio dengan kualitas tinggi minimal 16kHz dengan durasi 10-30 detik
- Untuk single speaker upload 1 file voice sample
- Untuk multi-speaker upload beberapa file sesuai jumlah pembicara yang diinginkan
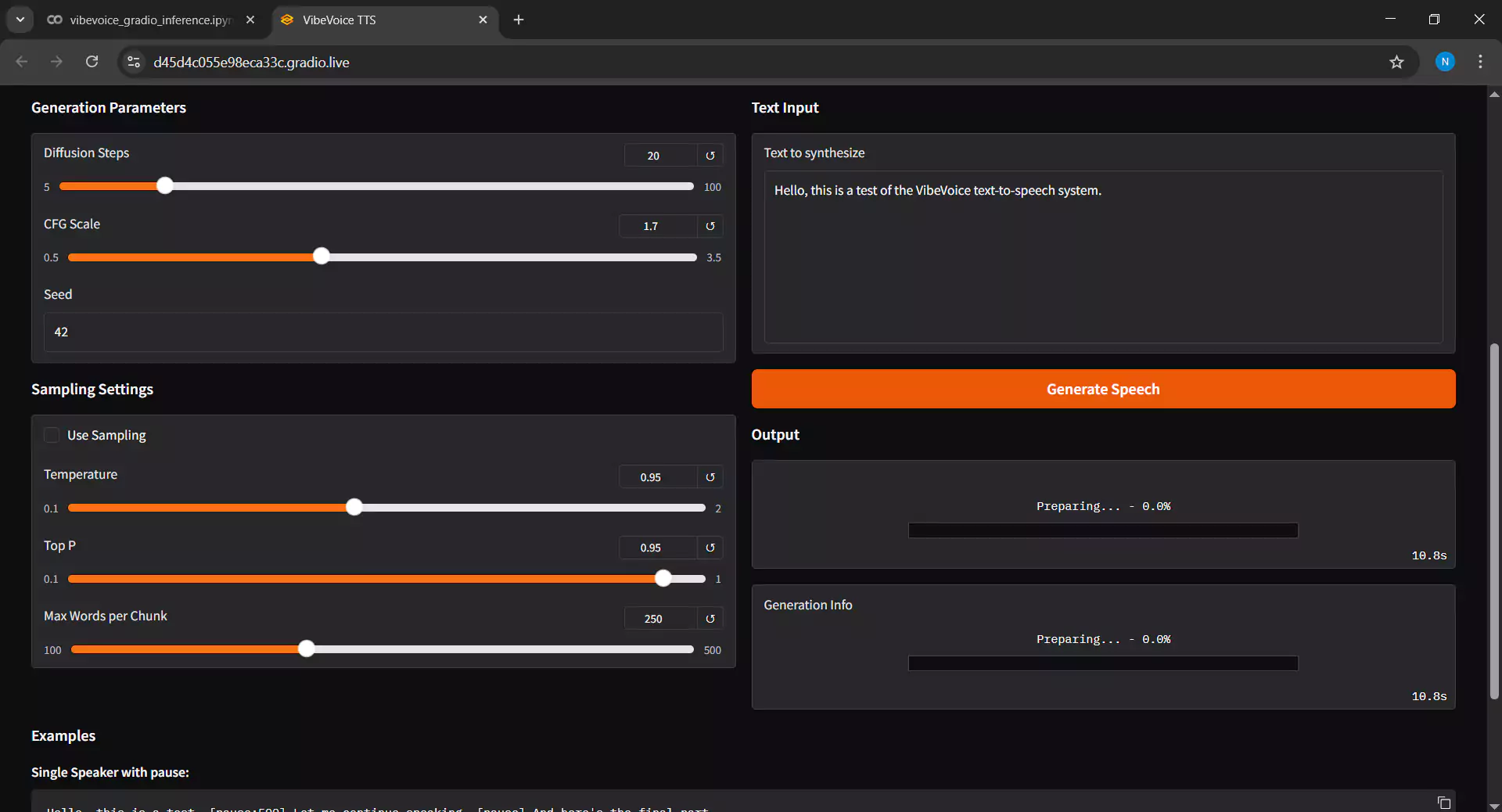
7. Mengatur Parameter Inference
Sesuaikan pengaturan pada bagian Inference Settings dengan cara berikut
- Diffusion Steps dimana semakin tinggi nilai akan menghasilkan kualitas lebih baik namun waktu inference lebih lama, saran biarkan pada nilai default 20 saja.
- Guidance Scale berfungsi mengatur kedekatan dengan voice sample acuan. jika hasil terdengar kurang stabil naikkan nilainya diatas 2.0.
- Input Text diisi dengan teks dialog yang ingin diubah menjadi audio, teks mendukung hampir semua bahasa namun perlu diingat bahwa model ini akan lebih baik jika bahasa text sama dengan bahasa voice sample acuan.
- Klik Submit untuk memulai proses inference
8. Menunggu Proses Inference
Tunggu beberapa saat hingga proses inference selesai. Waktu yang dibutuhkan bergantung pada beberapa faktor berikut
- Panjang teks input dimana teks pendek membutuhkan 1-5 menit
- Nilai diffusion steps yang dipilih
- Kompleksitas audio yang dihasilkan
Progress bar akan menunjukkan kemajuan proses inference.
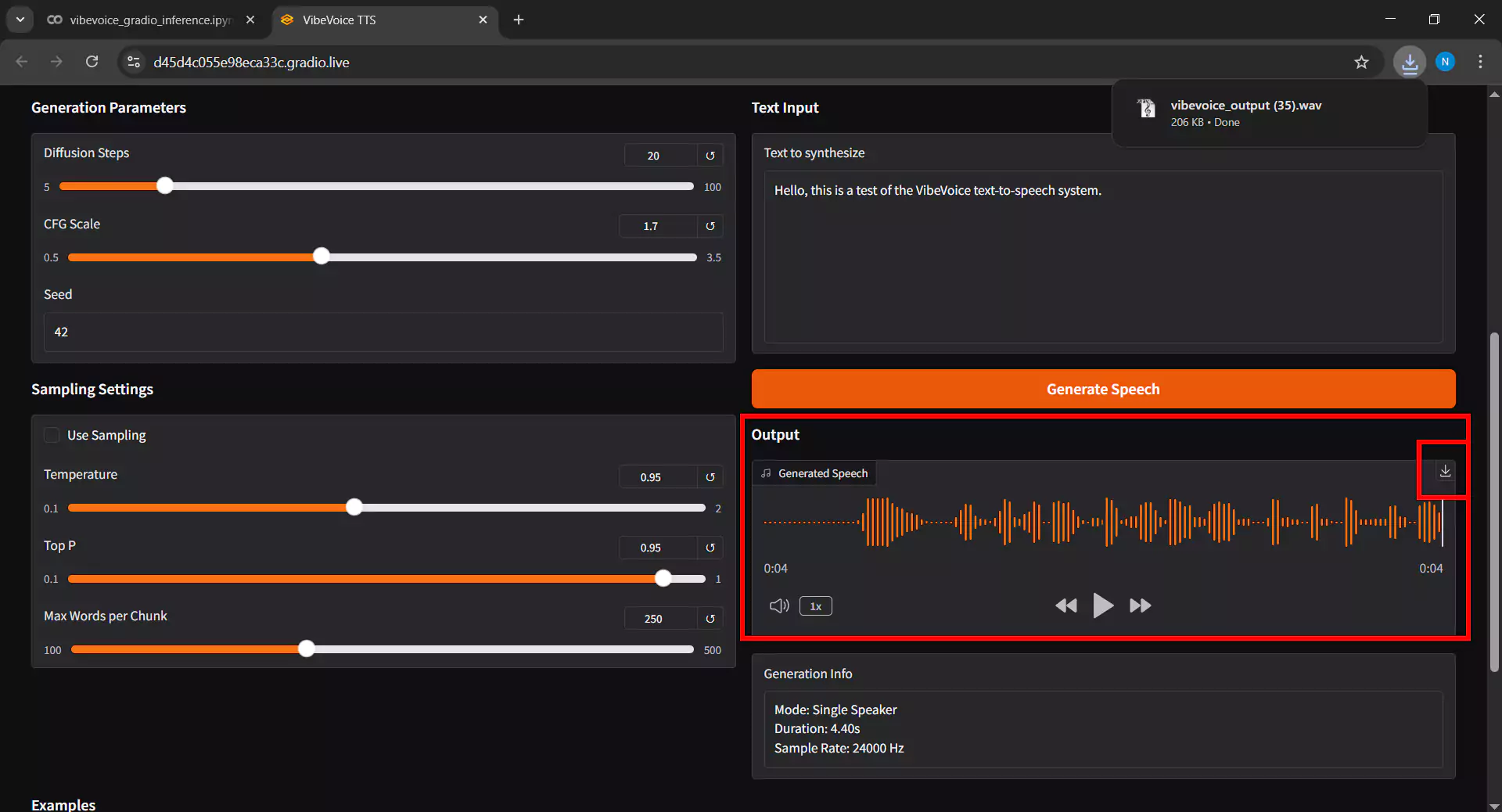
9. Memutar dan Mengunduh Audio
Setelah inference selesai lakukan langkah-langkah berikut
- Audio hasil akan muncul pada bagian Output Audio
- Klik tombol play untuk mendengarkan hasilnya
- Jika sudah puas dengan hasilnya, klik tombol Download untuk menyimpan file audio ke perangkat Anda
- Format output biasanya adalah WAV dengan kualitas tinggi
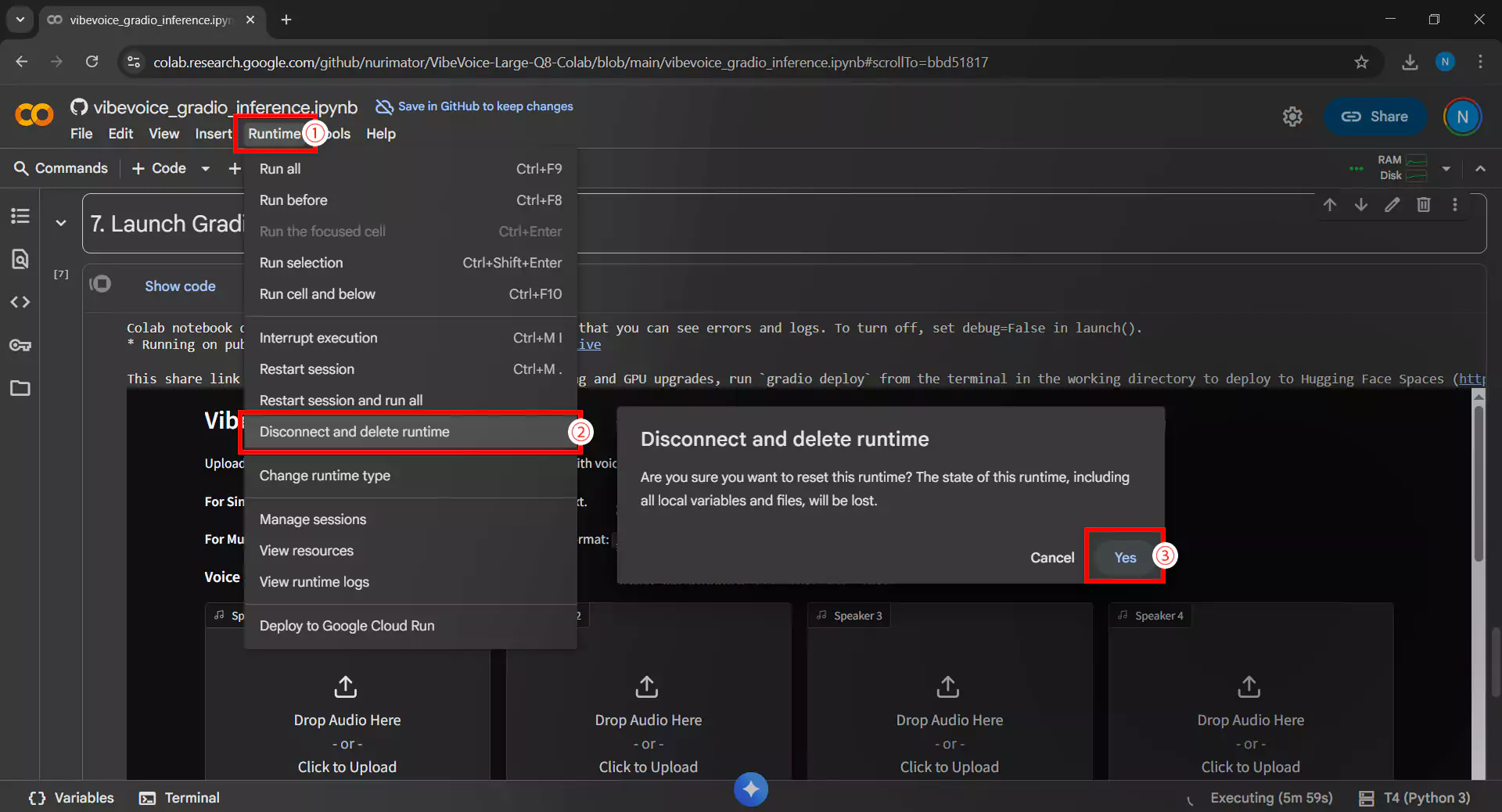
10. Menutup Runtime
Setelah selesai menggunakan VibeVoice, wajib memutuskan koneksi runtime dengan cara berikut
- Klik menu Runtime lalu Disconnect and delete runtime
- Atau klik ikon RAM/Disk di pojok kanan atas, lalu pilih Disconnect
Penting untuk diingat bahwa langkah ini mencegah pemborosan kuota GPU gratis Google Colab dan memungkinkan pengguna lain menggunakan sumber daya tersebut.
Penutup
Dengan memanfaatkan Google Colab, Anda dapat mengakses teknologi text-to-speech VibeVoice secara gratis tanpa investasi hardware mahal. Meskipun tier gratis memiliki batasan waktu penggunaan GPU beberapa jam per hari, ini sudah lebih dari cukup untuk bereksperimen dan menghasilkan audio percakapan multi-speaker berkualitas tinggi.
Selalu gunakan teknologi suara sintetis secara etis dan bertanggung jawab. Hindari penggunaan untuk deepfake, penipuan, atau tujuan yang merugikan orang lain. Semoga panduan ini bermanfaat dan selamat berkreasi dengan VibeVoice di Google Colab!



